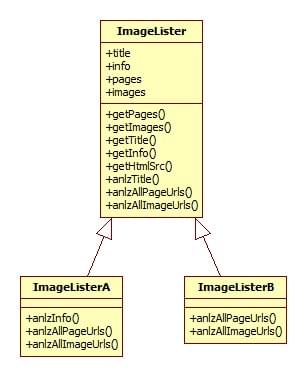
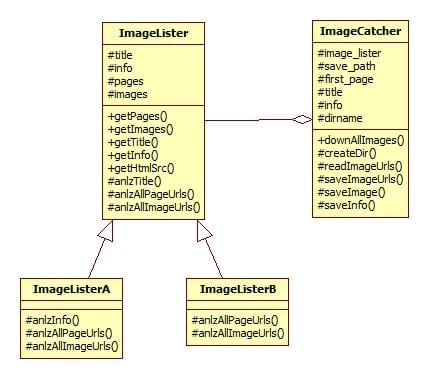
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
|
import os
from time import clock
import urlparse
from imagelistera import ImageListerA
from ulib import uopen, uclose, formatSize
IMAGE_URL_FILE = "image_urls.txt"
IMAGE_INFO_FILE = "image_info.txt"
class ImageCatcher(object):
def __init__(self, save_path, image_lister):
self.image_lister = image_lister
self.save_path = save_path
self.first_page = image_lister.getFirstPage()
self.title = image_lister.getTitle()
self.info = image_lister.getInfo()
self.dirname = os.path.join(save_path, self.title);
self.__createDir(self.dirname, verbose=False)
print self.title
self.downAllImages()
def __createDir(self, dirname, verbose=True):
if not os.path.exists(dirname):
os.makedirs(dirname)
if verbose:
print u"已创建:%s" % dirname
return True
else:
if verbose:
print u"已存在:%s" % dirname
return False
def downAllImages(self, verbose=True):
filename = os.path.join(self.dirname, IMAGE_URL_FILE)
if os.path.exists(filename):
if verbose:
print u"已存在:%s" % filename
images = self.__readImageUrls(filename, verbose)
else:
images = self.__saveImageUrls(filename, verbose)
self.images = images
imageNum = len(images)
i = 0
for image in images:
i += 1
if verbose:
print "%d/%d" % (i, imageNum)
print image
self.__saveImage(image)
filename = os.path.join(self.dirname, IMAGE_INFO_FILE)
self.__saveInfo(filename, verbose)
def __readImageUrls(self, filename, verbose=True):
f = open(filename, "r")
images = []
for line in f:
images.append(line.rstrip("\n"))
f.close()
if verbose:
print u"搜索到:%d 张" % len(images)
return images
def __saveImageUrls(self, filename, verbose=True):
images = self.image_lister.getImages()
if verbose:
print u"搜索到:%d 张" % len(images)
f = open(filename, "w")
for image in images:
f.write(image)
f.write("\n")
f.close()
if verbose:
print u"已写入:%s" % filename
return images
def __saveImage(self, url, verbose=True):
basename = url.split("/")[-1]
dirname = self.dirname
assert(os.path.exists(dirname))
filename = os.path.join(dirname, basename)
file_size = 0
if os.path.exists(filename):
print u"文件已存在:%s" % filename
else:
u = uopen(url)
if u is None:
return
block_size = 8192
downloaded_size = 0
length = u.info().getheaders("Content-Length")
if length:
file_size = int(length[0])
print u"文件大小:%s" % formatSize(file_size)
f = open(filename, "wb")
print u"正在下载:%s" % url
start = clock()
try:
while True:
buffer = u.read(block_size)
if not buffer:
break
downloaded_size += len(buffer);
f.write(buffer)
if file_size:
print "%2.1f%%\r" % (float(downloaded_size * 100) / file_size),
else:
print '...'
except BaseException, e:
print e
f.close()
if os.path.exists(filename):
os.remove(filename)
print u"已删除损坏的文件:%s", filename
exit()
finally:
uclose(u)
f.close()
print u"文件已保存:%s" % os.path.abspath(filename)
end = clock()
spend = end - start
print u"耗时:%.2f 秒" % spend
print u"平均速度:%.2fKB/s" % (float(file_size) / 1024 / spend)
def __saveInfo(self, filename, verbose=True):
if not os.path.exists(filename):
info = self.image_lister.getInfo()
f = open(filename, "w")
f.write(self.first_page)
f.write("\n")
if self.title:
f.write(self.title.encode("utf-8"))
f.write("\n")
if self.info:
f.write(self.info.encode("utf-8"))
f.write("\n")
if verbose:
print u"已写入:%s" % filename
return True
else:
if verbose:
print u"已存在:%s" % filename
return False
if __name__ == "__main__":
lister = ImageListerA("http://*************************************.htm")
ImageCatcher("pics", lister)
|