PLEG unhealthy 导致节点状态不断在 Ready/NotReady 之间切换问题
现象
- 收到告警提示 PLEG 延时升高(240s)
- 节点状态在 Ready 和 NotReady 之间频繁切换
- 有 pod 处于 Terminating 状态
排查和原因分析
查看 kubelet PLEG 相关日志,发现大量 PLEG 超时日志:
1 | Nov 27 10:10:07 xq68 kubelet[24562]: E1127 10:10:07.444787 24562 generic.go:271] PLEG: pod apiserver-inspection-workers-ds-1542964416453270535-6vhmt/qiniu-ranger failed reinspection: rpc error: code = DeadlineExceeded desc = context deadline exceeded |
PLEG (Pod Lifecycle Event Generator) 是 kubelet 定期检查节点上每个 pod 状态的逻辑,它内部缓存了节点所有 pod 的状态,每次通过 relist 时从 container runtime (dockerd) 获取 pod (也就是 pod 包含的所有 container) 的最新状态,然后和当前缓存比较,产生 PodLifecycleEvent。然后遍历所有的 events,更新 pod 状态缓存后将该 event 发送至 event channel。部分代码如下:
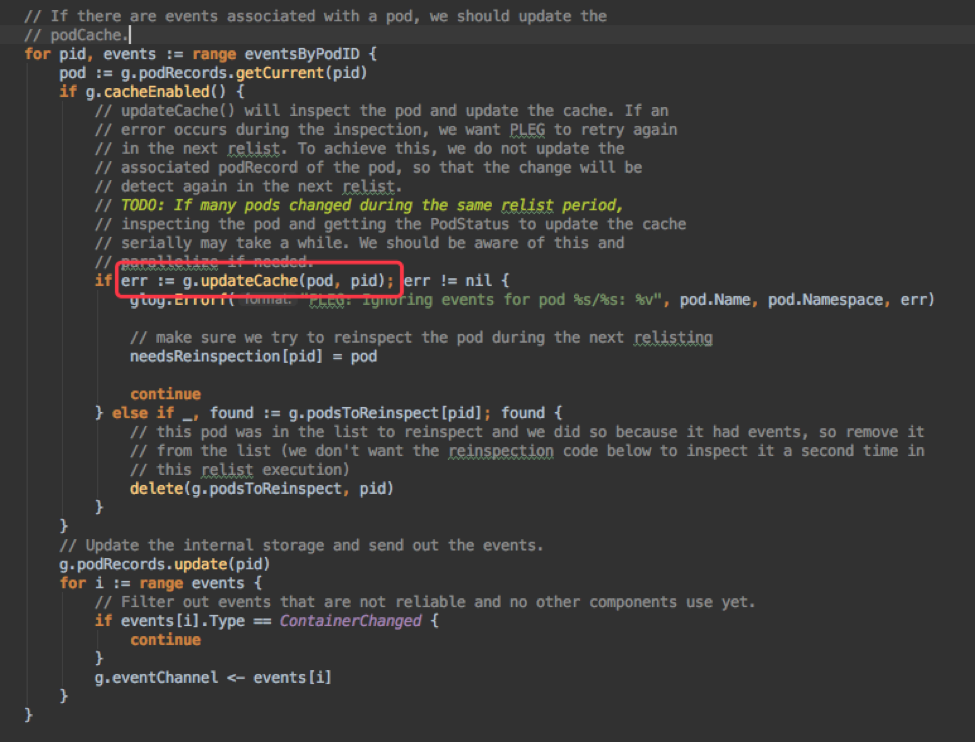
而问题就出在更新 Pod 缓存的逻辑,首先 PLEG 更新缓存是串行的,也就是前一个 Pod 执行成功了,后一个 Pod 才能开始;其次,更新缓存会调用 container runtime 的 GetPodStatus 接口来获取 Pod 状态(通过 rpc 获取容器状态和 Pod IP);而 rpc 调用是阻塞的,默认 120s (2min) 超时;PLEG 只要发现两次 relist 间隔超过 3min,就会认为 PLEG unhealthy,将节点设为 NotReady。
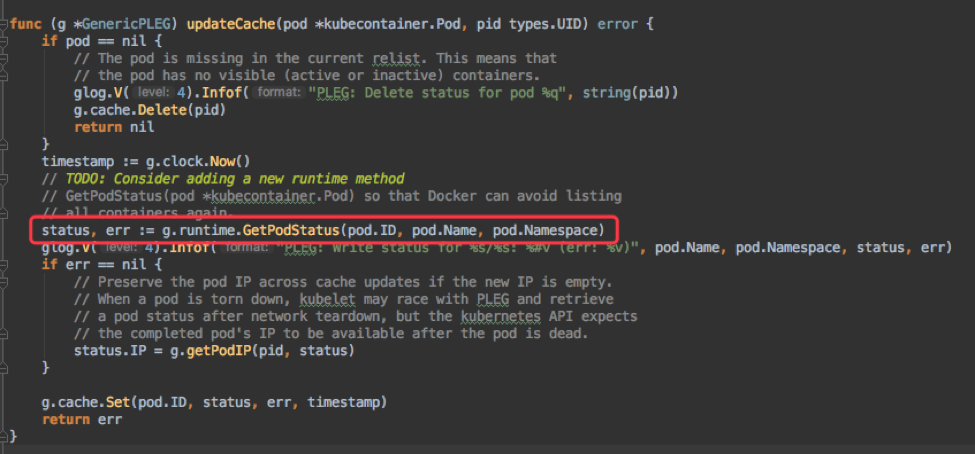
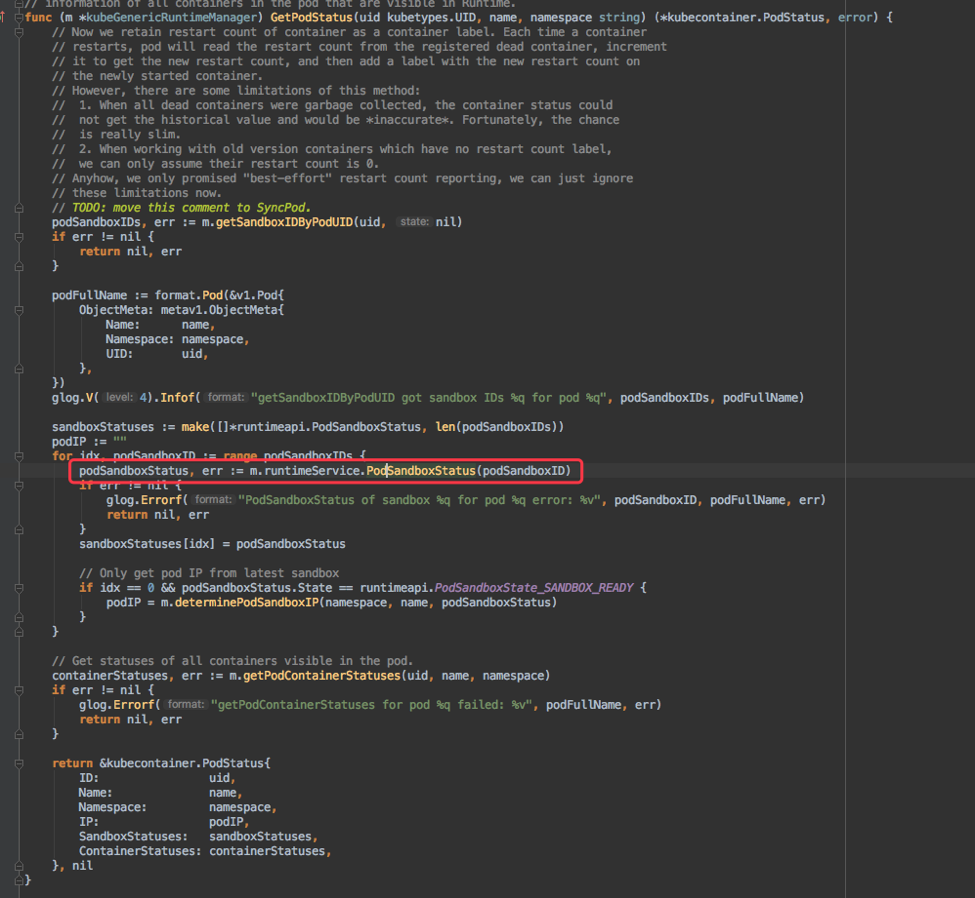
上面的 GetPodStatus 中有调用 cri 的 rpc 接口 PodSandboxStatus 和 ListContainers/ContainerStatus 分别获取 pause 容器和其他容器的状态。
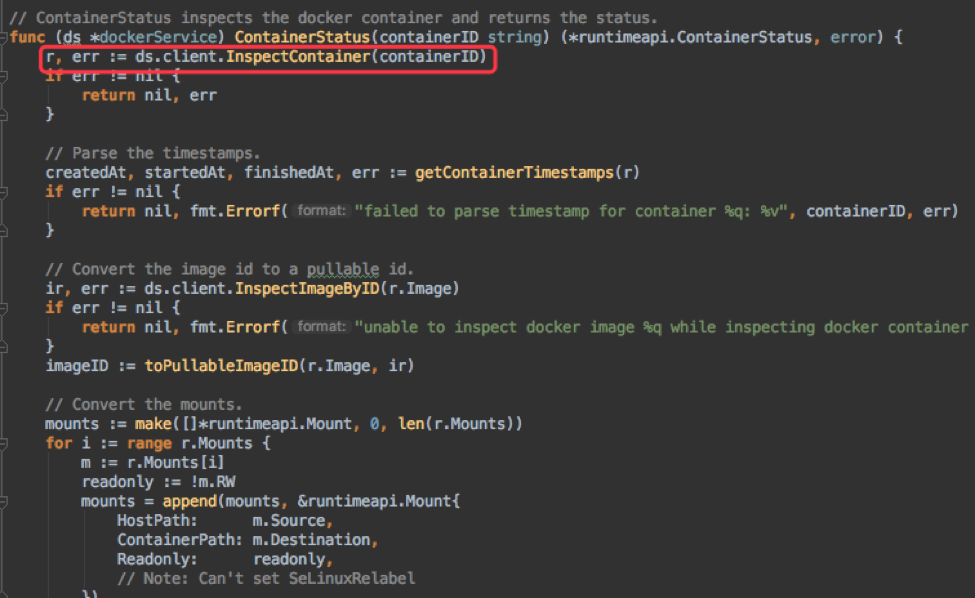
其中 ListContainers/ContainerStatus 里只会从 docker daemon 获取容器信息,而 PodSandboxStatus 不仅会从 docker daemon 获取 pause 容器信息,还会从 CNI 通过 GetPodNetworkStatus 接口获取 pod ip。这几个请求都是 grpc 请求,且超时时间都是 2min,如果中间因为各种原因 hang 住,会阻塞 2min 才能超时返回。
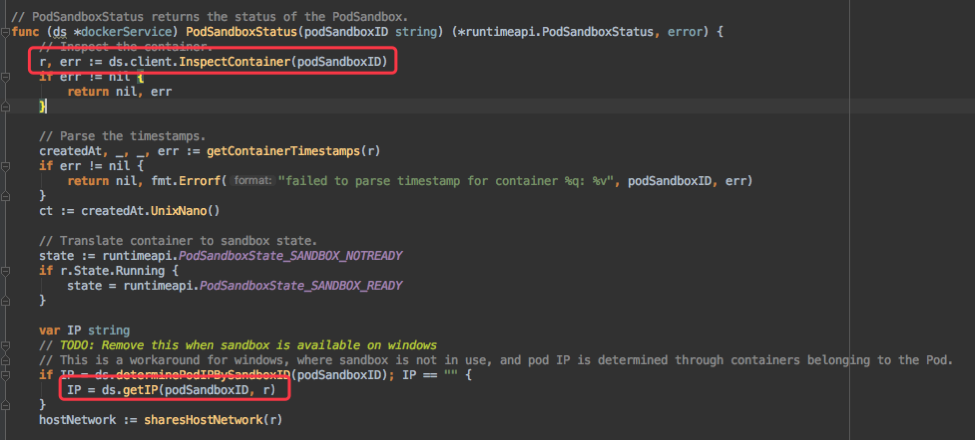
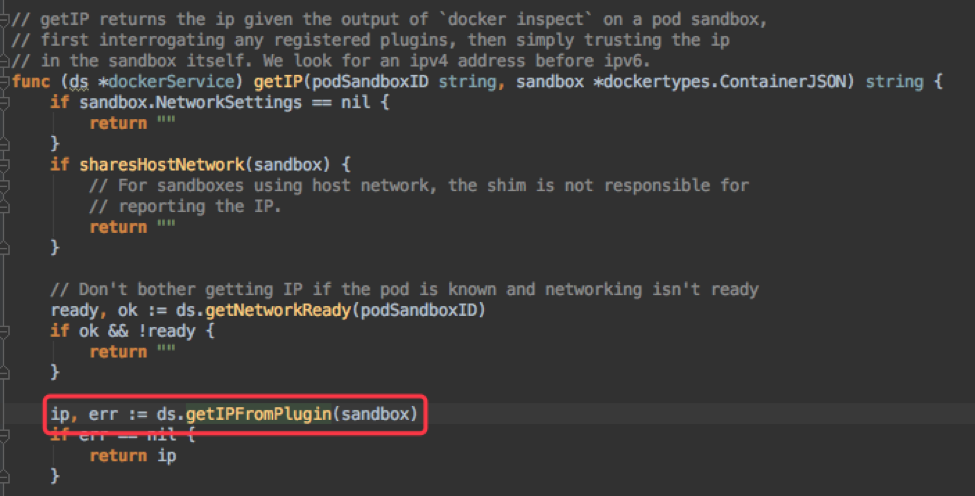
简单整理了整个调用逻辑如下:
1 | grpc http grpc |
同时由上面代码分析,PLEG 超时的原因,就是在更新某个 Pod 状态时,kubelet 通过 rpc 调用 docker daemon 或者 network plugin 时超时了。
调用 docker daemon 超时的原因有:
docker daemon hang 住。
调用 network plugin 超时的原因有:
network plugin 是利用 command exec 方式调用的, 因为各种原因进程不退出,会导致调用 hang 住。
调用 network plugin 还有个细节,就是每次调用前会按照 pod 加锁,所以只要一次调用 hang 住,后面的调用都会 hang 住,等待锁释放。
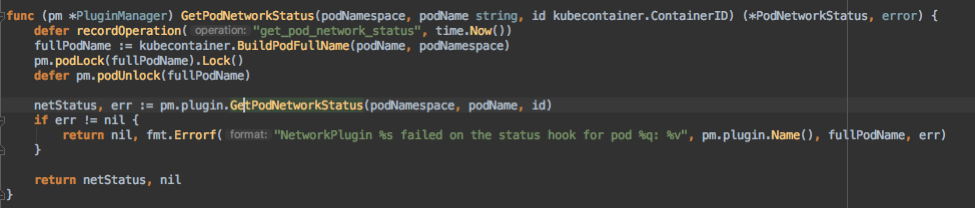
但是为什么对一个 Pod 调用 GetPodStatus 时 grpc 超时会导致 PLEG unhealthy 呢?我们先看看两个逻辑:
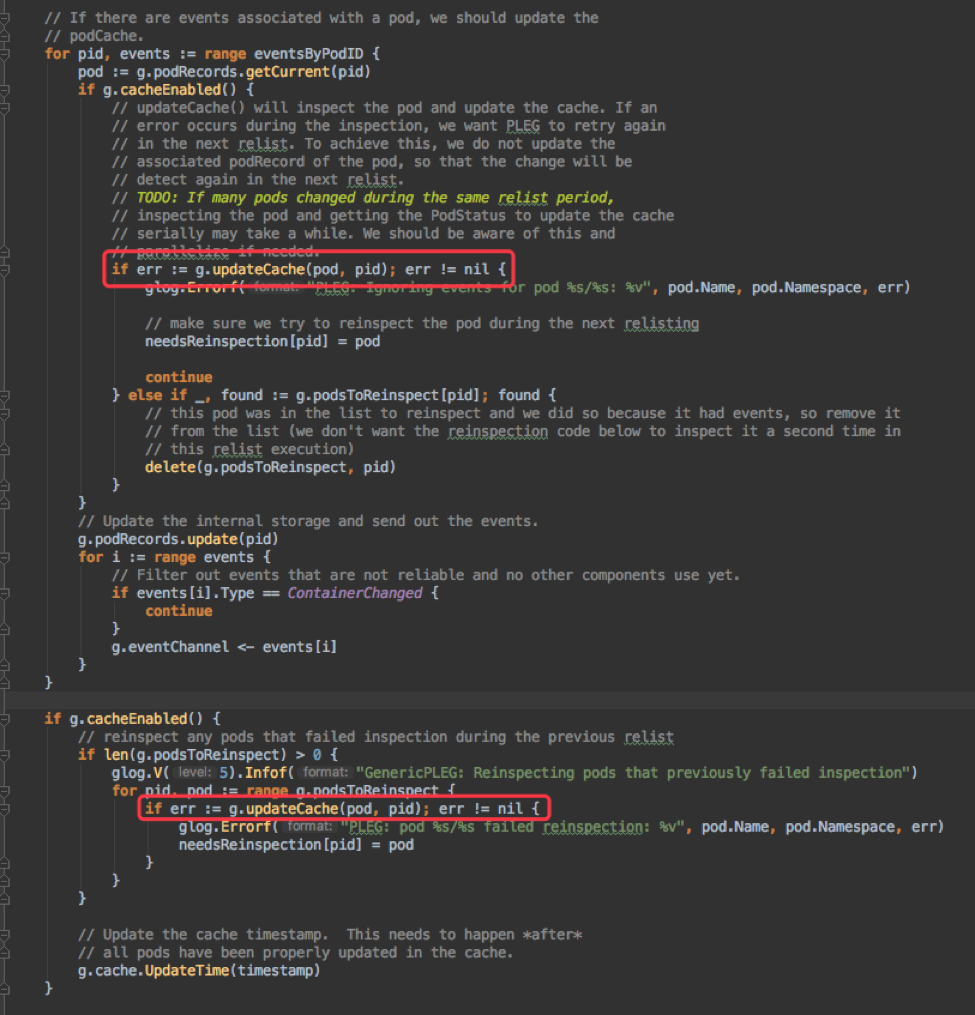
一是 relist 时的 updateCache 逻辑:
PLEG 每次 relist 时不仅要对当前状态有更新的 Pod 进行一次状态获取,还要对上次获取失败的 Pod 重新执行一次状态获取。也就是说,如果一个 grpc 请求的超时是 2min,那么假设一个 Pod 有问题,会将单次 relist 耗时放大至 4min。
二是 PLEG healthy check 逻辑:

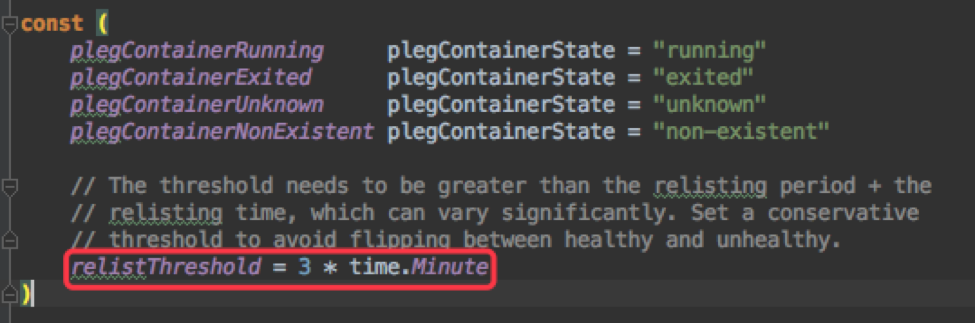
Runtime Health Checker 会定时调用 PLEG 的 Healty 函数对 PLEG 执行状态进行检测,从而判断节点的健康状况。每次检测时,只要判断距离上次执行完 relist 的时间大于 3 分钟,上层逻辑就会认为节点不健康了,便会根据结果将节点设置为 NotReady。
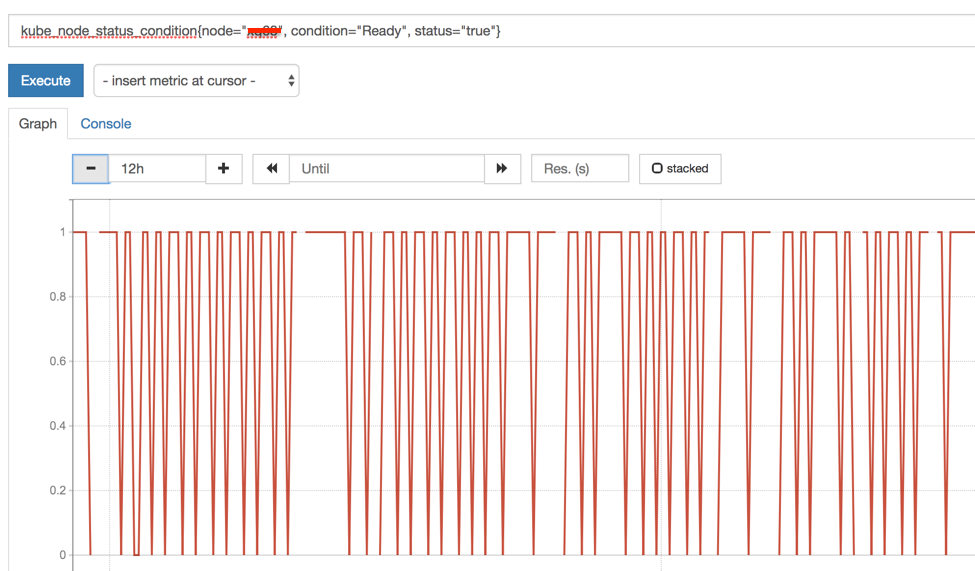
现在的场景是 PLEG relist 会执行,但是每次执行对于有问题的 Pod 要执行两次 updateCache/GetPodStatus,也就是等两次超时需要 4min 时间。Runtime Healthy Checker 每隔 100ms ~ 5s 执行一次,因此在 4min 内,前 3min 的 health check 是成功的,成功之后会将节点标记为 Ready,而 3min 后的 1min 内 healthy check 会失败,kubelet 又会将节点标记为 NotReady。
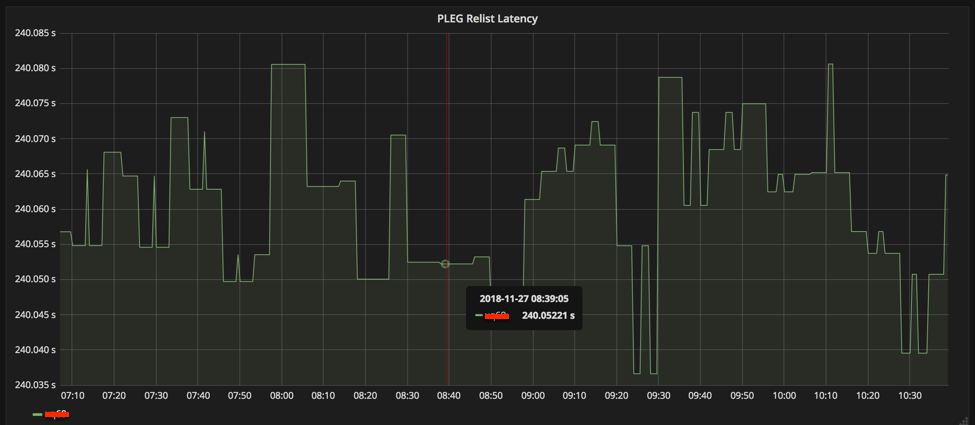
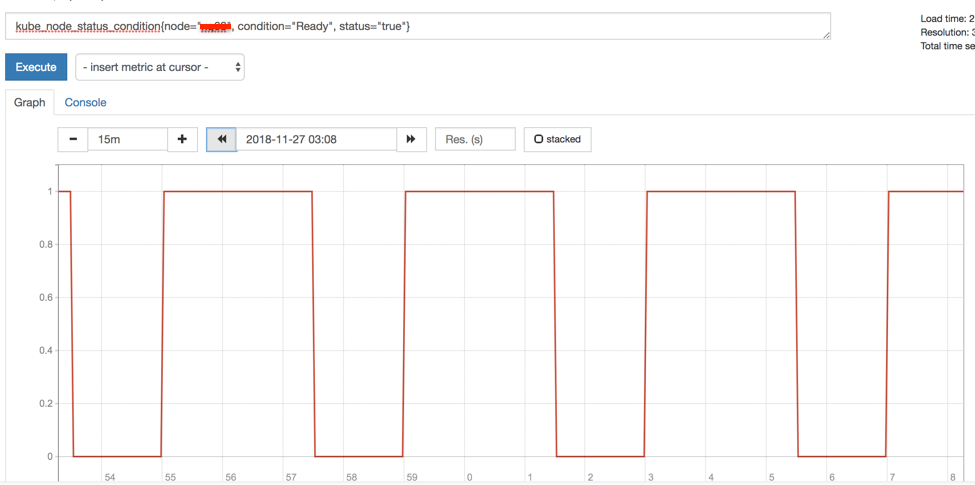
这个也能从监控图像上得到证实,如下图,ready status == 1 的间隔是 3min,ready status == 0 的间隔是 1min。
接下来我们一步步确认是哪个组件出了问题导致的:
确认 docker daemon 状态,看状态获取接口是否正常:
1 | curl --unix-socket /var/run/docker.sock http:/containers/40cddec6426e280b8e42a07ca5c8711d18557f3163c2541efd39462ccba10e39/json |
结果正常返回。
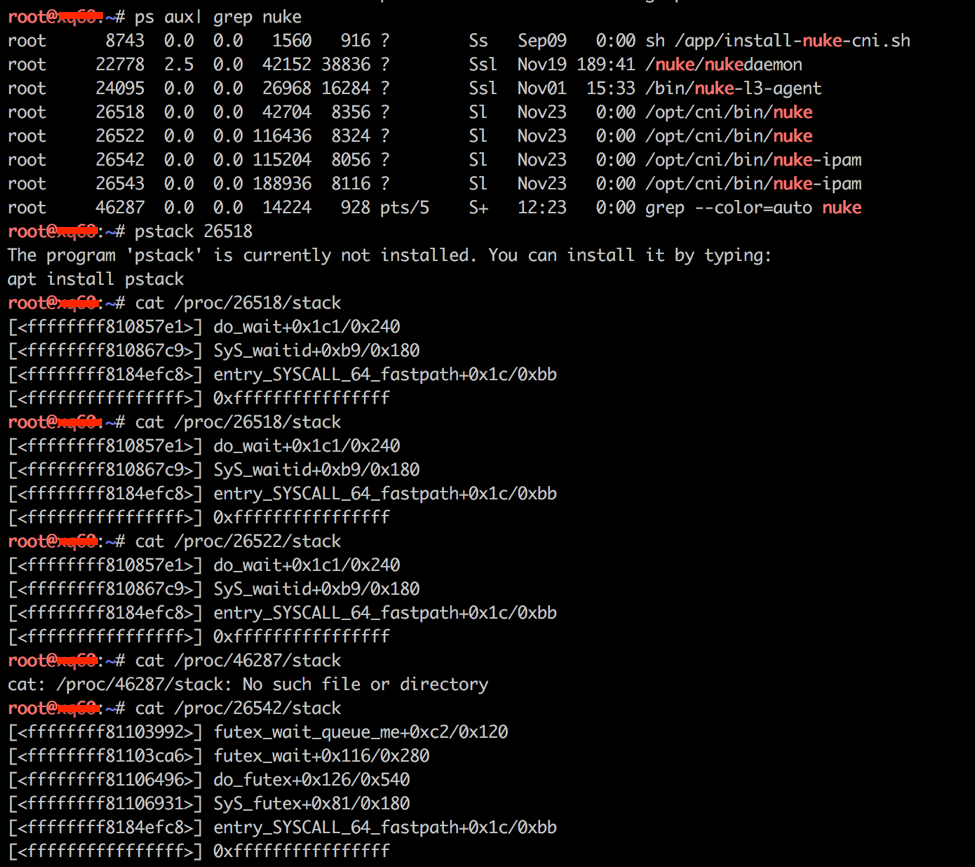
再查看网络组件进程状态,发现 nuke 和 nuke-ipam 两个进程从 2018-11-23 启动后一直没有退出(今天是 2018-11-27)。正常情况下,nuke 和 nkue-ipam 只在 kubelet 通过 cni 调用时执行,执行成功后会立即退出,而现在没有退出是个异常。因此判断问题可能出在 nuke 组件上。
1 | root@xq68:~# ps aux | grep nuke |
之前出现同样的问题时,为方便排查,我保存了 nuke 相关的 stack 信息,具体原因还需要网络组协助排查。
另外,如果网络方案为 calico,calico 进程 Z 住也会导致该问题:

解决
解决方式有:(选一种即可)
删除问题容器(一般都是 pause 容器)
1
2docker ps -a | grep apiserver-inspection-workers-ds-1542964416453270535-6vhmt
docker rm -f <container_id>删除后 kubelet 已经找不到这个容器,会认为 sandbox 已经 stop 成功,就不会再继续执行 PodSandBoxStatus 调用 cri 和 cni,从而就不会触发有问题的逻辑了。
重启 kubelet(待验证)
对于 neutron 网络方案,手动 kill 掉 hang 住的 nuke 和 nuke-ipam,network plugin 强行返回错误,kubelet 会继续执行后续逻辑。
改进
优化 kubelet PLEG 逻辑
- 考虑并行执行,一个 Pod 有问题时不影响整个 PLEG relist 耗时;
- 缩小 rpc 超时时间(目前 2min),对于正常场景来说,调用 cri 和 cni 都用不了这么长的时间。缩小超时可以减小单个 Pod 超时对 PLEG 整体的影响;
- 优化 updateCache 逻辑,保证每次 relist 对同一个 Pod 只进行一次状态获取。
修复 network plugin
寻找 network plugin hang 住的原因并修复。
优化监控告警
- pleg latency > 240s for 15min -> error 短信、slack 告知
- pleg latency > 240s -> warning slack 告知
相关问题
PLEG unhealthy 导致节点状态不断在 Ready/NotReady 之间切换问题